Apa
itu Clustering ?
Clustering atau klasterisasi adalah metode pengelompokan data. Menurut
Tan, 2006 clustering adalah sebuah
proses untuk mengelompokan data ke dalam beberapa cluster atau
kelompok sehingga data dalam satu cluster memiliki
tingkat kemiripan yang maksimum dan data antar cluster memiliki
kemiripan yang minimum.
Clustering merupakan proses partisi satu set objek data ke dalam himpunan bagian yang
disebut dengan cluster. Objek yang di dalam cluster memiliki kemiripan karakteristik
antar satu sama lainnya dan berbeda dengan cluster yang
lain. Partisi tidak dilakukan secara manual melainkan dengan suatu
algoritma clustering. Oleh karena itu, clustering sangat berguna dan bisa menemukan group atau kelompokyang tidak dikenal dalam
data. Clustering banyak digunakan dalam berbagai
aplikasi seperti misalnya pada business inteligence, pengenalan
pola citra, web search, bidang ilmu biologi, dan untuk
keamanan (security). Di dalam business inteligence, clustering bisa mengatur banyak customer ke dalam banyaknya kelompok. Contohnya
mengelompokan customer ke dalam beberapa cluster dengan kesamaan karakteristik yang
kuat. Clustering juga dikenal sebagai data segmentasi
karena clustering mempartisi banyak data set ke dalam
banyak group berdasarkan kesamaannya. Selain itu clustering juga bisa sebagai outlier detection.
1.
Clustering merupakan metode segmentasi data yang sangat berguna
dalam prediksi dan analisa masalah bisnis tertentu. Misalnya Segmentasi pasar,
marketing dan pemetaan zonasi wilayah.
2.
Identifikasi obyek dalam bidang
berbagai bidang seperti computer vision dan image processing.
Konsep dasar Clustering
Hasil clustering yang baik akan menghasilkan tingkat
kesamaan yang tinggi dalam satu kelas dan tingkat kesamaan yang rendah antar
kelas. Kesamaan yang dimaksud merupakan pengukuran secaranumeric terhadap dua
buah objek. Nilai kesamaan antar kedua objek akan semakin tinggi jika kedua objek
yang dibandingkan memiliki kemiripan yang tinggi. Begitu juga dengan
sebaliknya. Kualitas hasil clustering sangat
bergantung pada metode yang dipakai. Dalam clustering dikenal
empat tipe data. Keempat tipe data pada tersebut ialah:
1.
Variabel berskala interval
2.
Variabel biner
3.
Variabel nominal, ordinal, dan rasio
4.
Variabel dengan tipe lainnya.
Metode clustering juga harus dapat mengukur kemampuannya
sendiri dalam usaha untuk menemukan suatu pola tersembunyi pada data yang
sedang diteliti. Terdapat berbagai metode yang dapat digunakan untuk mengukur
nilai kesamaan antar objek-objek yang dibandingkan. Salah satunya ialah
dengan weighted Euclidean Distance. Euclidean distance
menghitung jarak dua buah point dengan mengetahui nilai dari masing-masing
atribut pada kedua poin tersebut. Berikut formula yang digunakan untuk
menghitung jarak dengan Euclidean distance:

Keterangan:
N = Jumlah record data
K= Urutan field data
r= 2
µk= Bobot field yang diberikan user
Jarak
adalah pendekatan yang umum dipakai untuk menentukan kesamaan atau
ketidaksamaan dua vektor fitur yang dinyatakan dengan ranking. Apabila nilai ranking yang
dihasilkan semakin kecil nilainya maka semakin dekat/tinggi kesamaan antara
kedua vektor tersebut. Teknik pengukuran jarak dengan metode Euclidean menjadi
salah satu metode yang paling umum digunakan. Pengukuran jarak dengan metode
euclidean dapat dituliskan dengan persamaan berikut:

dimana v1
dan v2 adalah dua vektor yang jaraknya akan dihitung dan N menyatakan
panjang vektor.
Syarat Clustering
Menurut
Han dan Kamber, 2012, syarat sekaligus tantangan yang harus dipenuhi oleh suatu
algoritma clustering adalah:
1.
Skalabilitas
Suatu
metode clustering harus mampu menangani data dalam jumlah
yang besar. Saat ini data dalam jumlah besar sudah sangat umum digunakan dalam
berbagai bidang misalnya saja suatu database. Tidak hanya berisi ratusan objek,
suatu database dengan ukuran besar bahkan berisi lebih dari jutaan objek.
2.
Kemampuan analisa beragam bentukdata
Algortima
klasteriasi harus mampu dimplementasikan pada berbagai macam bentuk data
seperti data nominal, ordinal maupun gabungannya.
3.
Menemukan cluster dengan
bentuk yang tidak terduga
Banyak
algoritma clustering yang menggunakan
metode Euclidean atau Manhattan yang
hasilnya berbentuk bulat. Padahal hasil clustering dapat
berbentuk aneh dan tidak sama antara satu dengan yang lain. Karenanya
dibutuhkan kemampuan untuk menganalisa cluster dengan
bentuk apapun pada suatu algoritma clustering.
3.
Kemampuan untuk dapat menangani
noise
Data
tidak selalu dalam keadaan baik. Ada kalanya terdapat data yang rusak, tidak
dimengerti atau hilang. Karena system inilah, suatu algortima clustering dituntut untuk mampu menangani data
yang rusak.
4.
Sensitifitas terhadap perubahan
input
Perubahan
atau penambahan data pada input dapat menyebabkan terjadi perubahan pada cluster yang telah ada bahkan bisa
menyebabkan perubahan yang mencolok apabila menggunakan algoritma clustering yang memiliki tingkat sensitifitas
rendah.
5.
Mampu melakukan clustering untuk data dimensi tinggi
Suatu
kelompok data dapat berisi banyak dimensi ataupun atribut. Untuk itu diperlukan
algoritma clustering yang mampu
menangani data dengan dimensi yang jumlahnya tidak sedikit.
6.
Interpresasi dan kegunaan
Hasil
dari clustering harus dapat diinterpretasikan dan
berguna.
Metode clustering secara umum dapat dibagi menjadi dua
yaitu hierarchical clusteringdan partitional clustering(Tan, 2011). Sebagai tambahan,
terdapat pula metode Density-Based dan Grid–Based yang juga sering diterapkan dalam
implementasi clustering. Berikut penjelasannya:
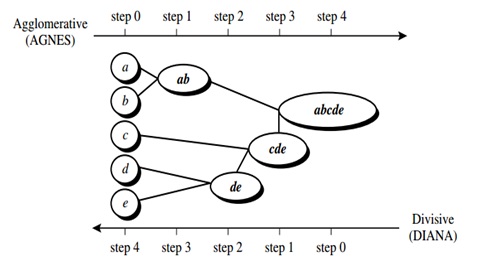
Pada hierarchical clusteringdata dikelompokkan melalui
suatu bagan yang berupa hirarki, dimana terdapat penggabungan dua grup yang
terdekat disetiap iterasinya ataupun pembagian dari seluruh set data
kedalam cluster.

Gambar 1.1
Hierarchical Clustering
(Sumber:Han
dkk, 2012)
Langkah
melakukan Hierarchical clustering:
1.
Identifikasi item dengan jarak terdekat
2.
Gabungkan item itu kedalam satu cluster
3.
Hitung jarak antar cluster
4.
Ulangi dari awal sampai semua
terhubung
Contoh
metode hierarchy clustering:
1.
Single link
Nilai kemiripan dua
clusters U dan V dihitung berdasarkan nilai kemiripan maksimum diantara anggota
kedua clusters tersebut

2.
Complete link
Nilai kemiripan dua clusters
dihitung berdasarkan nilai kemiripan minimum diantara anggota kedua clusters
tersebut

3.
UPGMA ( Average Link )
Nilai kemiripan dua
clusters dihitung berdasarkan nilai kemiripan rata-rata diantara anggota kedua clusters tersebut

Dimana |U| adalah
banyaknya data pada clusters U dan cu
adalah centroid untuk cluster U
2 Partitional Clustering
Partitional
clusteringyaitu data dikelompokkan ke dalam
sejumlah cluster tanpa adanya struktur hirarki antara
satu dengan yang lainnya. Pada metode partitional clusteringsetiap cluster memiliki titik pusat cluster (centroid) dan secara umum metode
ini memiliki fungsi tujuan yaitu meminimumkan jarak (dissimilarity)
dari seluruh data ke pusat cluster masing-masing.
Contoh metode partitional clustering:
K-Means, Fuzzy K-means dan Mixture Modelling.

Gambar 1.2 Proses Clustering Obyek Menggunakan metode
k-Means
(Sumber:Han dkk, 2012)
a.
Mixture Modelling (Mixture Modeling)
Mixture modelling (mixture
modeling) merupakan metode pengelompokan data yang mirip dengan k-means dengan
kelebihan penggunaan distribusi statistik dalam mendefinisikan setiap cluster
yang ditemukan. Dibandingkan dengan k-means yang hanya menggunakan cluster
center, penggunaan distribusi statistik ini mengijinkan kita untuk:
·
Memodel data yang
kita miliki dengan setting karakteristik yang berbeda-beda
·
Jumlah cluster yang
sesuai dengan keadaan data bisa ditemukan seiring dengan proses pemodelan
karakteristik dari masing-masing cluster
·
Hasil pemodelan
clustering yang dilaksanakan bisa diuji tingkat keakuratannya
Distribusi statistik yang
digunakan bisa bermacam-macam mulai dari yang digunakan untuk data categorical
sampai yang continuous, termasuk di antaranya distribusi binomial, multinomial,
normal dan lain-lain. Beberapa distribusi yang bersifat tidak normal seperti
distribusi Poisson, von-Mises, Gamma dan Student t, juga diterapkan untuk bisa
mengakomodasi berbagai keadaan data yang ada di lapangan. Beberapa pendekatan
multivariate juga banyak diterapkan untuk memperhitungkan tingkat keterkaitan
antara variabel data yang satu dengan yang lainnya.
b.
K-Means ( Yang dijelaskan mendalam)
Apa
itu K-Means Clustering ?
K-means merupakan algoritma clustering. K-means
Clustering adalah salah satu “unsupervised machine learning
algorithms” yang paling sederhana dan populer. K-Means Clustering adalah
suatu metode penganalisaan data atau metode Data Mining yang
melakukan proses pemodelan tanpa supervisi (unsupervised) dan merupakan
salah satu metode yang melakukan pengelompokan data dengan sistem partisi.
Terdapat dua jenis data clustering yang sering dipergunakan dalam
proses pengelompokan data yaitu Hierarchical dan Non-Hierarchical,
dan K-Means merupakan salah satu metode data clustering
non-hierarchical atau Partitional Clustering. K-means
clustering merupakan salah satu metode cluster analysis
non hirarki yang berusaha untuk mempartisi objek yang ada kedalam satu atau
lebih cluster atau kelompok objek berdasarkan
karakteristiknya, sehingga objek yang mempunyai karakteristik yang sama
dikelompokan dalam satu cluster yang sama dan objek yang mempunyai
karakteristik yang berbeda dikelompokan kedalam cluster yang
lain.

Metode K-Means Clustering berusaha mengelompokkan
data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok
mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik
yang berbeda dengan data yang ada di dalam kelompok yang lain.

Dengan kata lain, metode K-Means Clustering bertujuan
untuk meminimalisasikan objective function yang diset dalam proses clustering dengan
cara meminimalkan variasi antar data yang ada di dalam suatu cluster dan
memaksimalkan variasi dengan data yang ada di cluster lainnya
juga bertujuan untuk menemukan grup dalam data, dengan jumlah grup yang
diwakili oleh variabel K. Variabel K sendiri adalah jumlah cluster yang
diinginkan. Membagi data menjadi beberapa kelompok. Algoritma ini menerima
masukan berupa data tanpa label kelas. Hal ini berbeda dengan supervised
learning yang menerima masukan berupa vektor (x1 , y1) ,
(x2 , y2) , …, (xi , yi), di mana xi merupakan
data dari suatu data pelatihan dan yi merupakan label kelas
untuk xi .

Pada algoritma pembelajaran ini, komputer mengelompokkan sendiri
data-data yang menjadi masukannya tanpa mengetahui terlebih dulu target
kelasnya. Pembelajaran ini termasuk dalam unsupervised learning. Masukan
yang diterima adalah data atau objek dan k buah kelompok (cluster)
yang diinginkan. Algoritma ini akan mengelompokkan data atau objek ke
dalam k buah kelompok tersebut. Pada setiap cluster terdapat
titik pusat (centroid) yang merepresentasikan cluster tersebut.
K-means ditemukan oleh beberapa
orang yaitu Lloyd (1957, 1982), Forgey (1965) , Friedman and Rubin (1967), and
McQueen (1967). Ide dari clustering pertama kali ditemukan oleh
Lloyd pada tahun 1957, namun hal tersebut baru dipublikasi pada tahun 1982.
Pada tahun 1965, Forgey juga mempublikasi teknik yang sama sehingga terkadang
dikenal sebagai Lloyd-Forgy pada beberapa sumber.
Data clustering menggunakan metode K-Means Clustering ini
secara umum dilakukan dengan algoritma dasar sebagai berikut:
1.
Tentukan jumlah cluster
2.
Alokasikan data ke dalam cluster secara random
3.
Hitung centroid/rata-rata
dari data yang ada di masing-masing cluster
4.
Alokasikan masing-masing data
ke centroid/rata-rata terdekat
5.
Kembali ke Step 3, apabila
masih ada data yang berpindah cluster atau apabila perubahan nilai centroid,
ada yang di atas nilai threshold yang ditentukan atau apabila
perubahan nilai pada objective function yang
digunakan di atas nilai threshold yang ditentukan

Menurut Daniel dan Eko, Langkah-langkah algoritma K-Means adalah
sebagai berikut:
·
Pilih secara acak k buah data
sebagai pusat cluster.
·
Jarak antara data dan pusat
cluster dihitung menggunakan Euclidean Distance. Untuk menghitung
jarak semua data ke setiap titik pusat cluster dapat
menggunakan teori jarak Euclidean yang dirumuskan sebagai
berikut: dimana: D (i,j) = Jarak data ke i ke pusat cluster j Xki = Data ke i
pada atribut data ke k Xkj = Titik pusat ke j pada atribut ke k
·
Data ditempatkan dalam cluster
yang terdekat, dihitung dari tengah cluster.
·
Pusat cluster baru
akan ditentukan bila semua data telah ditetapkan dalam cluster terdekat.
·
Proses penentuan pusat cluster dan
penempatan data dalam cluster diulangi sampai nilai centroid
tidak berubah lagi.
Algoritma untuk melakukan K-Means clustering adalah
sebagai berikut
1.
Pilih K buah titik centroid secara
acak
2.
Kelompokkan data sehingga
terbentuk K buah cluster dengan titik centroid dari
setiap cluster merupakan titik centroid yang
telah dipilih sebelumnya
3.
Perbaharui nilai titik centroid
4.
Ulangi langkah 2 dan 3 sampai
nilai dari titik centroid tidak lagi berubah
Proses pengelompokkan data ke dalam suatu cluster dapat
dilakukan dengan cara menghitung jarak terdekat dari suatu data ke sebuah
titik centroid.
Beberapa
Permasalahan yang Terkait Dengan K-Means Clustering
Beberapa permasalahan yang sering muncul pada saat menggunakan
metode K-Means untuk melakukan pengelompokan data adalah:
1.
Ditemukannya beberapa model
clustering yang berbeda
2.
Pemilihan jumlah cluster yang
paling tepat
3.
Kegagalan untuk converge
4.
Outliers
5.
Bentuk cluster
6.
Overlapping
Permasalahan 1
umumnya
disebabkan oleh perbedaan proses inisialisasi anggota masing-masing cluster.
Proses initialisasi yang sering digunakan adalah proses inisialisasi secara
random. Dalam suatu studi perbandingan, proses inisialisasi secara random
mempunyai kecenderungan untuk memberikan hasil yang lebih baik dan independent,
walaupun dari segi kecepatan untuk convergen lebih lambat.
Permasalahan 2
merupakan
masalah laten dalam metode K-Means. Beberapa pendekatan telah digunakan dalam
menentukan jumlah cluster yang paling tepat untuk suatu dataset yang dianalisa
termasuk di antaranya Partition Entropy (PE) dan GAP Statistics.
Permasalahan 3
kegagalan
untuk converge, secara teori memungkinkan untuk terjadi dalam metode Hard
K-Means maupun Fuzzy K-Means. Kemungkinan ini akan semakin besar terjadi untuk
metode Hard K-Means, karena setiap data di dalam dataset dialokasikan secara
tegas (hard) untuk menjadi bagian dari suatu cluster tertentu. Perpindahan
suatu data ke suatu cluster tertentu dapat mengubah karakteristik model clustering
yang dapat menyebabkan data yang telah dipindahkan tersebut lebih sesuai untuk
berada di cluster semula sebelum data tersebut dipindahkan. Demikian juga
dengan keadaan sebaliknya.
Kejadian
seperti ini tentu akan mengakibatkan pemodelan tidak akan berhenti dan
kegagalan untuk converge akan terjadi. Untuk Fuzzy K-Means, walaupun ada,
kemungkinan permasalahan ini untuk terjadi sangatlah kecil, karena setiap data
diperlengkapi dengan membership function (Fuzzy K-Means) untuk menjadi anggota
cluster yang ditemukan.
Permasalahan 4
merupakan
permasalahan umum yang terjadi hampir di setiap metode yang melakukan pemodelan
terhadap data. Khusus untuk metode K-Means hal ini memang menjadi permasalahan
yang cukup menentukan.
Beberapa
hal yang perlu diperhatikan dalam melakukan pendeteksian outliers dalam proses
pengelompokan data termasuk bagaimana menentukan apakah suatu data item
merupakan outliers dari suatu cluster tertentu dan apakah data dalam jumlah
kecil yang membentuk suatu cluster tersendiri dapat dianggap sebagai outliers.
Proses ini memerlukan suatu pendekatan khusus yang berbeda dengan proses
pendeteksian outliers di dalam suatu dataset yang hanya terdiri dari satu
populasi yang homogen.
Permasalahan 5
menyangkut bentuk cluster yang ditemukan.
Tidak seperti metode data clustering lainnya, K-Means umumnya tidak
mengindahkan bentuk dari masing-masing cluster yang mendasari model yang
terbentuk, walaupun secara natural masing-masing cluster umumnya berbentuk
bundar. Untuk dataset yang diperkirakan mempunyai bentuk yang tidak biasa,
beberapa pendekatan perlu untuk diterapkan.
Permasalahan 6
masalah
overlapping sebagai permasalahan terakhir sering sekali diabaikan karena
umumnya masalah ini sulit terdeteksi. Hal ini terjadi untuk metode Hard K-Means
dan Fuzzy K-Means, karena secara teori, metode ini tidak diperlengkapi feature
untuk mendeteksi apakah di dalam suatu cluster ada cluster lain yang
kemungkinan tersembunyi.
Hard K-Means dan Fuzzy K-Means
Secara
mendasar, ada dua cara pengalokasian data kembali ke dalam masing-masing
cluster pada saat proses iterasi clustering. Kedua cara tersebut adalah
pengalokasian dengan cara tegas (hard), dimana data item secara tegas
dinyatakan sebagai anggota cluster yang satu dan tidak menjadi anggota cluster
lainnya, dan dengan cara fuzzy, dimana masing-masing data item diberikan nilai
kemungkinan untuk bisa bergabung ke setiap cluster yang ada. Kedua cara
pengalokasian tersebut diakomodasikan pada dua metode Hard K-Means dan Fuzzy K-Means.
Perbedaan
di antara kedua metode ini terletak pada asumsi yang dipakai sebagai dasar
pengalokasian.
a.
Hard K-Means
Pengalokasian
kembali data ke dalam masing-masing cluster dalam metode Hard K-Means
didasarkan pada perbandingan jarak antara data dengan centroid setiap cluster
yang ada. Data dialokasikan ulang secara tegas ke cluster yang mempunyai
centroid terdekat dengan data tersebut. Pengalokasian ini dapat dirumuskan
sebagai berikut:

Hard
K-Means
dimana:
aik : Keanggotaan data ke-k ke cluster ke-i
vi : Nilai centroid cluster ke-i
b. Fuzzy K-Means
Metode Fuzzy K-Means (atau lebih sering disebut
sebagai Fuzzy C-Means) mengalokasikan kembali data ke dalam
masing-masing cluster dengan memanfaatkan teori Fuzzy. Teori ini
mengeneralisasikan metode pengalokasian yang bersifat tegas (hard) seperti yang
digunakan pada metode Hard K-Means. Dalam metode Fuzzy K-Means dipergunakan
variabel membership function, uik, yang merujuk
pada seberapa besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu
cluster.
Pada Fuzzy K-Means yang diusulkan oleh Bezdek, diperkenalkan
juga suatu variabel myang merupakan weighting exponent dari membership
function. Variabel ini dapat mengubah besaran pengaruh dari membership
function, uik, dalam proses clustering
menggunakan metode Fuzzy K-Means. Nilai m mempunyai
wilayah nilai m>1.
Sampai sekarang ini tidak ada ketentuan yang jelas berapa
besar nilai m yang optimal dalam melakukan
proses optimasi suatu permasalahan clustering. Nilai myang umumnya digunakan
adalah 2.
Membership
function untuk suatu data ke suatu cluster tertentu dihitung menggunakan rumus
sebagai berikut:

dimana:
uik : Membership function data ke-k ke cluster
ke-i
vi : Nilai centroid cluster ke-i
m : Weighting Exponent
Membership function, uik, mempunyai
wilayah nilai 0 ≤ uik ≤ 1. Data item yang
mempunyai tingkat kemungkinan yang lebih tinggi ke suatu kelompok akan
mempunyai nilai membership function ke kelompok tersebut yang mendekati angka 1
dan ke kelompok yang lain mendekati angka 0.
Untuk menghitung centroid cluster ke-i, vi, digunakan rumus sebagai berikut:

dimana:
N :Jumlah data
m : Weighting exponent
uik : Membership function data ke-k ke cluster
ke-i
Objective Function
Objective Function adalah pernyataan kuantitatif dari kasus optimasi,
sebagai contoh: memaksimumkan benefit, dengan menentukan biaya operasi minimum.
Objective Function yang digunakan untuk metode Hard K-Means, adalah sebagai
berikut:

Objective Function Hard K-Means
dimana:
N : Jumlah data
c : Jumlah cluster
aik : Keanggotaan data ke-k ke cluster ke-i
vi : Nilai centroid cluster ke-i
Nilai aik mempunyai
nilai 0 atau 1. Apabila suatu data merupakan anggota suatu kelompok maka
nilai aik=1 dan sebaliknya.
Untuk metode Fuzzy K-Means, Objective Function yang digunakan adalah sebagai
berikut:

Objective Function Fuzzy Means
dimana:
N : Jumlah data
c : Jumlah cluster
m : Weighting exponent
uik : Membership function data ke-k ke cluster
ke-i
vi : Nilai centroid cluster ke-i
Di sini uik bisa
mengambil nilai mulai dari 0 sampai 1.
Semi-Supervised Classification?
K-Means merupakan metode data clustering
yang digolongkan sebagai metode pengklasifikasian yang bersifat unsupervised
(tanpa arahan). Pengkategorian metode-metode
pengklasifikasian data antara supervised dan unsupervised classification
didasarkan pada adanya dataset yang data itemnya sudah sejak awal mempunyai
label kelas atau tidak. Untuk data yang sudah mempunyai label kelas, metode
pengklasifikasian yang digunakan merupakan metode supervised classification dan untuk data yang
belum mempunyai label kelas, metode pengklasifikasian yang digunakan adalah
metode unsupervised classification.
Selain
masalah optimasi pengelompokan data ke masing-masing cluster, data clustering
juga diasosiasikan dengan permasalahan penentuan jumlah cluster yang paling
tepat untuk data yang dianalisa. Untuk kedua jenis K-Means, baik Hard K-Means
dan Fuzzy K-Means, yang, penentuan jumlah cluster untuk dataset yang dianalisa
umumnya dilakukan secara supervised atau ditentukan dari awal oleh pengguna,
walaupun dalam penerapannya ada beberapa metode yang sering dipasangkan dengan
metode K-Means.
Karena
secara teori metode penentuan jumlah cluster ini tidak sama dengan metode
pengelompokan yang dilakukan oleh K-Means, kevalidan jumlah cluster yang
dihasilkan umumnya masih dipertanyakan.
Melihat
keadaan dimana pengguna umumnya sering menentukan jumlah cluster sendiri secara
terpisah, baik itu dengan menggunakan metode tertentu atau berdasarkan
pengalaman, di sini, kedua metode K-Means ini dapat disebut sebagai metode
semi-supervised classification, karena metode ini mengalokasikan data items ke
masing-masing cluster secara unsupervised dan menentukan jumlah cluster yang
paling sesuai dengan data yang dianalisa secara supervised
Karakteristik K-Means
1.
K-Means
sangat cepat dalam proses clustering
2.
K-Means
sangat sensitif pada pembangkitan centroid awal secara random
3.
Memungkinkan
suatu cluster tidak mempunyai anggota
4.
Hasil
clustering dengan K-Means bersifat tidak unik (selalu berubah-ubah) – terkadang
baik, terkadang jelek
5.
K-means
sangat sulit untuk mencapai global optimum
Memperhatikan
input dalam algoritma K-Means, dapat
dikatakan bahwa algoritma ini hanya mengolah
data kuantitatif atau numerik.
Sebuah basis data tidak mungkin hanya berisi satu macam
tipe data saja, akan tetapi beragam tipe.
Sebuah basis data dapat berisi data-data dengan tipe sebagai berikut: binary,
nominal, ordinal, interval dan ratio.
Berbagai macam atribut dalam basis data yang berbeda tipe disebut
sebagai data multivariate.
Tipe data seperti nominal dan ordinal harus diolah terlebih
dahulu menjadi data numerik (bisa dilakukan dengan cara diskritisasi),
sehingga dapat diberlakukan algoritma K-Means dalam
pembentukan clusternya.
Kelebihan
dan kekurangan K-Means
Ada beberapa kelebihan pada algoritma k-means, yaitu:
1.
Mudah untuk diimplementasikan
dan dijalankan.
2.
Waktu yang dibutuhkan untuk
menjalankan pembelajaran ini relatif cepat.
3.
Mudah untuk diadaptasi.
4.
Umum digunakan.
Algoritma k-means memiliki beberapa kelebihan, namun ada
kekurangannya juga. Kekurangan dari algoritma tersebut yaitu :
1.
Sebelum algoritma dijalankan, k
buah titik diinisialisasi secara random sehingga
pengelompokkan data yang dihasilkan dapat berbeda-beda. Jika nilai random untuk
inisialisasi kurang baik, maka pengelompokkan yang dihasilkan pun menjadi
kurang optimal.
2.
Dapat terjebak dalam masalah
yang disebut curse of dimensionality. Hal ini dapat terjadi
jika data pelatihan memiliki dimensi yang sangat tinggi (Contoh jika data
pelatihan terdiri dari 2 atribut maka dimensinya adalah 2 dimensi. Namun jika
ada 20 atribut, maka akan ada 20 dimensi). Salah satu cara kerja algoritma ini
adalah mencari jarak terdekat antara k buah titik dengan titik
lainnya. Jika mencari jarak antar titik pada 2 dimensi, masih mudah dilakukan.
Namun bagaimana mencari jarak antar titik jika terdapat 20 dimensi. Hal ini
akan menjadi sulit.
3.
Jika hanya terdapat beberapa
titik sampel data, maka cukup mudah untuk menghitung dan mencari titik terdekat
dengan k titik yang diinisialisasi secara random. Namun
jika terdapat banyak sekali titik data (misalnya satu milyar buah data), maka
perhitungan dan pencarian titik terdekat akan membutuhkan waktu yang lama.
Proses tersebut dapat dipercepat, namun dibutuhkan struktur data yang lebih
rumit seperti kD-Tree atau hashing.
Contoh Kasus Perhitungan K-Means Clustering
Ditentukan
banyaknya cluster yang dibentuk dua (k=2). Banyaknya cluster harus lebih kecil dari pada banyaknya
data (k<n).

Inisialisasi
centroid dataset pada tabel dataset diatas adalah C1 = {1 , 1} dan C2 = {2 , 1}. Inisialiasasi
centroid dapat ditentukan secara manual ataupun random.
Untuk
pengulangan berikutnya (pengulangan ke-1 sampai selesai), centroid baru
dihitung dengan menghitung
nilai rata-rata data pada setiap cluster. Jika centroid baru berbeda dengan
cntroid sebelumnya, maka proses dilanjutkan ke langkah berikutnya. Namun jika
centroid yang baru dihitung sama dengan centroid sebelumnya, maka proses
clustering selesai.
Rumus yang digunakan untuk menghitung distance space atau jarak data dengan centroid menggunakan
Euclidiean Distance.

Perulangan ke 1
Jarak
data dengan Centroid
C1 adalah:

Pengulangan ke-1 C1 K-means
Jarak
data dengan Centroid
C2 adalah:

Pengulangan ke-1 C2 K-means
Untuk seterusnya,
hitung jarak pada setiap baris data, dan hasilnya seperti pada tabel dibawah.

Kelompokan
data sesuai dengan cluster-nya, yaitu data yang memiliki jarak terpendek.
Contoh; karena d(x1,c1)
< d(x1,c2) maka x1 masuk ke dalam
cluster 1. Pada tabel diatas, data n=1 masuk ke dalam cluster 1 karena dc1 < dc2, sedangkan n=2,3,4
masuk ke dalam cluster 2 karena dc2 < dc1.

Setelah mendapatkan
label cluster untuk masing-masing data n=1,2,3,4 maka dicari nilai rata-ratanya
dengan menjumlahkan seluruh anggota masing-masing cluster dan dibagi jumlah
anggotanya.

Pengulangan
ke-2


Karena centroid tidak
mengalami perubahan (sama dengan centroid sebelumnya) maka proses clustering
selesai.
3. Clustering Dengan Pendekatan Automatic Mapping
Self-Organising Map (SOM)
Self-Organising Map (SOM) merupakan suatu tipe Artificial
Neural Networks yang di-training secara unsupervised. SOM menghasilkan map yang
terdiri dari output dalam dimensi yang rendah (2 atau 3 dimensi). Map ini
berusaha mencari property dari input data. Komposisi input dan output dalam SOM
mirip dengan komposisi dari proses feature scaling (multidimensional scaling).
Walaupun proses learning yang dilakukan mirip dengan
Artificial Neural Networks, tetapi proses untuk meng-assign input data ke map,
lebih mirip dengan K-Means dan kNN Algorithm. Adapun prosedur yang ditempuh
dalam melakukan clustering dengan SOM adalah sebagai berikut:
1. Tentukan
weight dari input data secara random
2. Pilih
salah satu input data
3. Hitung
tingkat kesamaan (dengan Eucledian) antara input data dan weight dari input
data tersebut dan pilih input data yang memiliki kesamaan dengan weight yang
ada (data ini disebut dengan Best Matching Unit (BMU))
4. Perbaharui
weight dari input data dengan mendekatkan weight tersebut ke BMU dengan rumus:
Wv(t+1)
= Wv(t) + Theta(v, t) x Alpha(t) x (D(t) – Wv(t))
Dimana:
· Wv(t): Weight pada saat ke-t
· Theta
(v, t): Fungsi neighbourhood yang tergantung pada Lattice distance antara BMU
dengan neuron v. Umumnya bernilai 1 untuk neuron yang cukup dekat dengan BMU,
dan 0 untuk yang sebaliknya. Penggunaan fungsi Gaussian juga memungkinkan.
·
Alpha (t): Learning Coefficient yang
berkurang secara monotonic
·
D(t): Input data
5. Tambah
nilai t, sampai t < Lambda, dimana Lambda adalah jumlah iterasi
4. Variasi Metode Clustering
a.
Quality Threshold Clustering Method
b.
Locality Sensitive Hashing
c.
Algoritma Rock
d.
Hierarchical Frequent Term-Base Clustering
e.
Suffix Tree Clustering
f.
Single Pass Clustering
g.
Neighborhood Clustering
h.
Sequence Clustering
i.
Spectral Clustering
j.
Clustering on Frequent Tree
k.
Latent Class Cluster Analysis a.k.a. Latent
Profile Analysis a.k.a. Mixture Model for Continuous Variabel
l.
Latent Class Analysis a.k.a. Mixture Model
for Categorical Variable
5. Hal-hal Terkait Dengan Clustering
a. Analisa Faktor
b. Singular Value Decomposition
c. Eigen Value and Eigen Vector
d. Similarity Measure
e. Feature Discretisation
f. Feature Selection
g. Feature Scaling
h. Indexing Method For Searching
6. Clustering Implementation
·
Document Clustering
Algorithm, Document Feature Extraction
·
Image Clustering
1. https://id.wikipedia.org/wiki/K-means
2. https://informatikalogi.com/algoritma-k-means-clustering/
4. https://ilmukomputer.org/wp-content/uploads/2018/05/agus-k-means-clustering.pdf
5. https://informatikalogi.com/algoritma-k-means-clustering/#4
6. https://wiragotama.github.io/resources/ebook/parts/JWGP-intro-to-ml-chap10
secured.pdf
8. https://yudiagusta.wordpress.com/clustering/




{kind=link}
No comments:
Post a Comment